Grpahql 적용 시 고민해 볼 점
Graphql이란 ?
Facebook에서 만든 엔드포인트가 하나인 api를 만드는 쿼리언어입니다. api를 요청하는 url은 하나고 요청하는 client가 무슨 데이터가 필요한지를 적어서 보낼 수 있습니다. Graphql이 무엇인지는 인터넷에서 이미 자세하게 나와 있습니다. (https://velopert.com/2318)
Graphql을 쓰면
- api를 만드는 유지보수가 없어지고
- 클라이언트 별 (웹, 안드로이드, iOS등) api를 따로 만들 필요가 없어집니다.
- response를 필요한 것만 받아서 overfetch 및 가공이 줄어들게 됩니다.
- 기존 데이터베이스 위에 스키마만 추가해서 적용할 수 있습니다.
기존 REST와는 전혀 다른 개념인데 과연 이렇게 장점만 있을지 적용하면서 문제되는 이슈는 없을지 스스로 고민하고 조사해봤습니다. 다소 주관적일 수 있는점 양해 부탁드립니다.
1. Graphql을 사용하게 되면 server에 있을 query 코드가 client에 들어가게 된다. 그럼 그만큼 client의 코드량이 늘어나지 않는지?
간단한 예시를 봅시다.
GraphQl 요청 시
query {
post(1) {
title
subject
author {
name
}
relatedPosts(first: 10) {
title
}
tags(first: 2) {
name
}
}
}
REST API 요청 시
http://api.dooray.com/posts/1
사실 코드량이 늘어나는 건 당연합니다. 얼핏 봐도 코드량 차이가 꽤 납니다. 대용량 서비스로 갈수록 쿼리량은 더더욱 차이가 날 것 같습니다. 쿼리만 해도 개별파일(.gpl)로 관리를 해야 할 것입니다.
그래서 클라이언트 입장에서는 코드관리면에서 REST보다는 복잡한 것 같다는 생각입니다. 서버에 있을 쿼리가 클라이언트로 옮겨가는 것이니깐요. REST도 파라미터가 있으니 양적인 측면에서 관리이슈가 같다라는 생각은 복잡한 어플리케이션에서 들어가는 쿼리를 생각하면 하지 않을 것입니다. 그만큼 서버로 오는 response의 양은 줄겠지만, request의 쿼리 데이터양이 늘어날 것입니다. 대충 10KB가 넘는다고 하네요.
다만 이것은 Graphql의 유연성을 얻기 위해 감수해야 하는 부분이라고 생각합니다. 클라이언트의 코드량이 늘지만 그만큼 Graphql의 장점인 자유도 높은 데이터를 뽑는 게 가능하고 가공해야 하는 부분이 줄어드니깐요.
그렇지만 사실 저뿐만이 아니라 수많은 사람이 고민하는 문제입니다. 어떻게 써야 좀 더 관리이슈를 줄이고 쉽게 사용할 수 있을까를 봐야 할 것 같습니다. 이는 어찌 보면 성능과도 연계된 부분이기도 합니다.
Persisted GraphQL Queries
긴 response를 해결하기 위해 graphql에는 persisted query라는 개념이 있습니다. 쿼리를 저장해둔다는 개념인데요. 따지고 보면 REST API와 일맥상통하는 부분이 있습니다. 같은 query를 api로 묶어준다라고 생각하면 될 것 같습니다.
Apollo에서는 2가지 방법을 소개하고 있습니다.
apollo-link-persisted-queries
- 해시를 통한 해결 방법으로 클라이언트 쪽에 코드를 넣고 서버의 아폴로 링크와 함께 동작합니다.
- 설치만 하면 되서 아주 간편합니다.
- 동작원리
- 쿼리를 요청하기 전에 클라이언트에서 쿼리의 해쉬값을 만들어 서버에 먼저 전송한다.
- 서버는 해당 해시값으로 쿼리가 있는지 없는지 본다.
- 없다면 서버는 쿼리를 찾을 수 없다고 클라이언트에 말하고 클라이언트는 쿼리를 보내준다. 그리고 서버는 해시값으로 쿼리를 레지스트리에 저장한다.
- 해당 해시로 쿼리가 저장되어 있으면 결과를 보내준다.
아래 그림을 참조하시면 쉬울 것 같습니다.
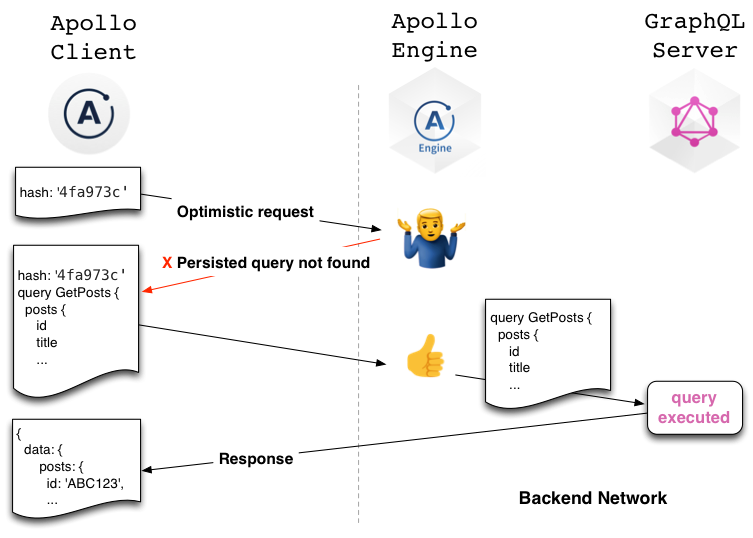
출처: https://dev-blog.apollodata.com/improve-graphql-performance-with-automatic-persisted-queries-c31d27b8e6ea
persistgraphql
- 간단한 미들웨어에 적합하게 생성된 툴입니다.
- 클라이언트 빌드 시에 persistgraphql를 실행하여 쿼리 파일과 혹은 스크립트에 들어 있는 쿼리들을 해시값/ID로 매핑된 쿼리맵을 만듭니다.
- 그럼 서버는 해당 쿼리맵을 이용하여 클라이언트와의 요청을 처리합니다.
- 이렇게 하면 대용량의 쿼리 전송 없이 서버사이드에서 처리할 수가 있습니다.
2. 클라이언트가 쿼리를 만들기 위해서는 스키마를 모두 알아야 한다. 그럼 기존과 다르게 서버의 스키마를 클라이언트와 공유해야 어떻게 쿼리를 보낼지 알 것 같은데 어떻게 해야 하나.
기존 REST를 쓸 때는 클라이언트 입장에서 데이터베이스 스키마를 알 필요는 전혀 없습니다. 풀스택 개발자뿐인 개발팀이 아닌 이상 적당한 규모의 서비스는 프론트앤드 인력과 백앤드 인력이 나뉘어 있습니다. 각자 자기 역할에 맞는 정도로만 알고 있기 때문에 서로 필요한 데이터를 공유하는 과정이 필요합니다.
저희 같은 경우는 REST API 문서를 공유해서 서로 커뮤니케이션을 합니다. 그런데 Graphql을 쓰게 되면 API 문서가 없습니다. Graphql은 스키마가 서버사이드에 있는데 어떤 방법으로든 스키마 파일을 클라이언트에게 공유할 방법이 필요합니다.
대부분 graphiql과 apollo devtools를 이용해서 서버가 graphql URL을 열어주면 클라이언트가 해당 URL에 접속해 직접 스키마를 보고 쿼리를 작성해보고 코드에 반영을합니다. 이렇게 하면
- 백앤드가 API 문서를 따로 관리할 필요가 없다.
- 클라리언트도 쉽게 쿼리를 작성해보고 테스트할 수 있다.
app.get('/graphql', graphqlHTTP({ schema: MyGraphQLSchema, graphiql: true }));
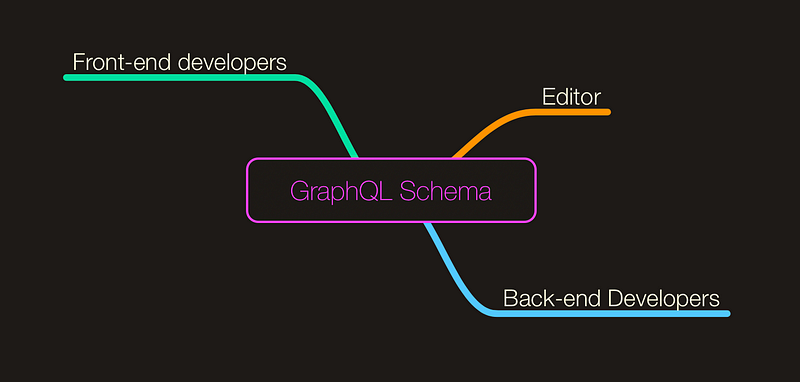
다만, 위 그림처럼 스키마를 모두가 바라보고 있는 상황입니다. 또 스키마가 프론트엔드가 주로 사용하는 만큼 누가 스키마 파일을 관리하고 편집할 것인지 각 서비스에 맞게 잘 정해야 할 것 같습니다. 참조
3. 복잡한 서비스의 경우 어쩌면 필연적으로 join과 n+1문제를 겪게 된다. graphql의 경우 이를 해결하거나 아니면 안 나도록 보장해 줄 수 있는지
with
4. 쿼리의 튜닝이 필요할 때가 있을 것 같은데 graphql의 쿼리가 실제로 어떻게 나가는지 알 방법이 있나?
사실 이 두 질문에 대한 답은 join-monster를 쓰면 해결이 됩니다. join-monster는 n+1문제도 해결하면서(완전해결은 힘들겠지만) 쿼리를 볼 수도 있습니다.
n+1문제는 이미 수많은 사람이 고민했습니다. 대표적으로 나오는 방법은 배치를 적용해서 처리하는 겁니다. Facebook에서 만든 data-loader를 사용했다는 아티클이 많습니다. 배치로드로 일괄처리 하여 n+1문제를 줄이고 거기에 더해 각 요청에 관하여 캐싱을 하여 성능상의 이점도 있습니다. 앤드포인트가 하나인 graphql에서는 클라이언트 캐싱이 조금 힘든데요. data-lodaer를 통해 캐싱할 수 있습니다. 다만, 자주 비워줘야 하는 캐싱 관리 포인트와 메모리 부족 등을 겪을 수 있습니다.
쿼리가 실제로 어떻게 나가는지는 join-monster를 사용하면 됩니다. 여기에 더해 data-loader가 하는 일을 대체할 수 있습니다. 캐싱은 해주지 않지만 하나의 요청에만 적용하던 일괄처리를 모든 요청에 관한 일괄처리해서 더 빠른 퍼포먼스를 내고 n+1을 해결 할 수 있다고 합니다. data-loader와 join-monster 비교
위와 같이 Grpahql의 쿼리가 실제로 어떤 SQL 쿼리로 바뀌는지 볼 수 있습니다. (graphql툴에도 적용이 가능합니다. )
5. 프로젝트가 너무 커서 바로 적용하기 무리에요. graphql과 rest를 동시에 사용할 순 없나요?
graphql용 서버프레임워크가 따로 있는 게 아닙니다. Apollo 같은 툴들은 모듈입니다.(물론 있을 수도 있습니다…) graphql API는 API대로 열어 놓고 rest API도 따로 쓰면 됩니다. graphql과 rest를 비교한 많은 글이 두 개의 개념 자체가 다르기 때문에 각각의 장점과 한계를 인지하고 있습니다. 프로젝트가 크면 당장 바꾸는 게 부담이 되니 graphql이 좀 더 필요한 부분은 먼저 적용하고 rest 유지가 필요한 부분은 유지하는 게 좋다는 생각입니다.
 위와 비슷한 구조
위와 비슷한 구조
아래는 추가 링크입니다.
- n+1문제에 관한 고민: http://samhogy.co.uk/2017/11/solving-the-graphql-n-plus-one-problem.html
- slow query가 있을시 로깅해주는 툴: https://github.com/sangria-graphql/sangria-slowlog
- graphql과 rest에서의 캐싱: https://philsturgeon.uk/api/2017/01/26/graphql-vs-rest-caching/
